MNIST Handwritten Digit Classification
A deep learning project to understand CNN architectures by training and comparing multiple models on the MNIST dataset with an interactive testing pipeline.
March 2026
Overview
This project is a hands-on learning exercise in deep learning and computer vision. It implements a complete training pipeline for classifying handwritten digits (0-9) from the MNIST dataset using convolutional neural networks (CNNs) built with PyTorch.
The goal was not just to get high accuracy, but to understand how and why different model architectures, data augmentation strategies, and training techniques affect performance. The project includes an interactive menu system to train models, visualize data, and test predictions on hand-drawn digits.
Features
- Three CNN architectures (1-layer, 2-layer, 3-layer) to compare how depth affects accuracy
- Data augmentation comparison — trains Model 3 with and without augmentation to measure its impact
- Interactive menu system for training, visualization, and testing without editing code
- Hand-drawn digit testing — draw your own digit and see the model predict it in real time
- Saliency maps — visualize which pixels the model focuses on when making predictions
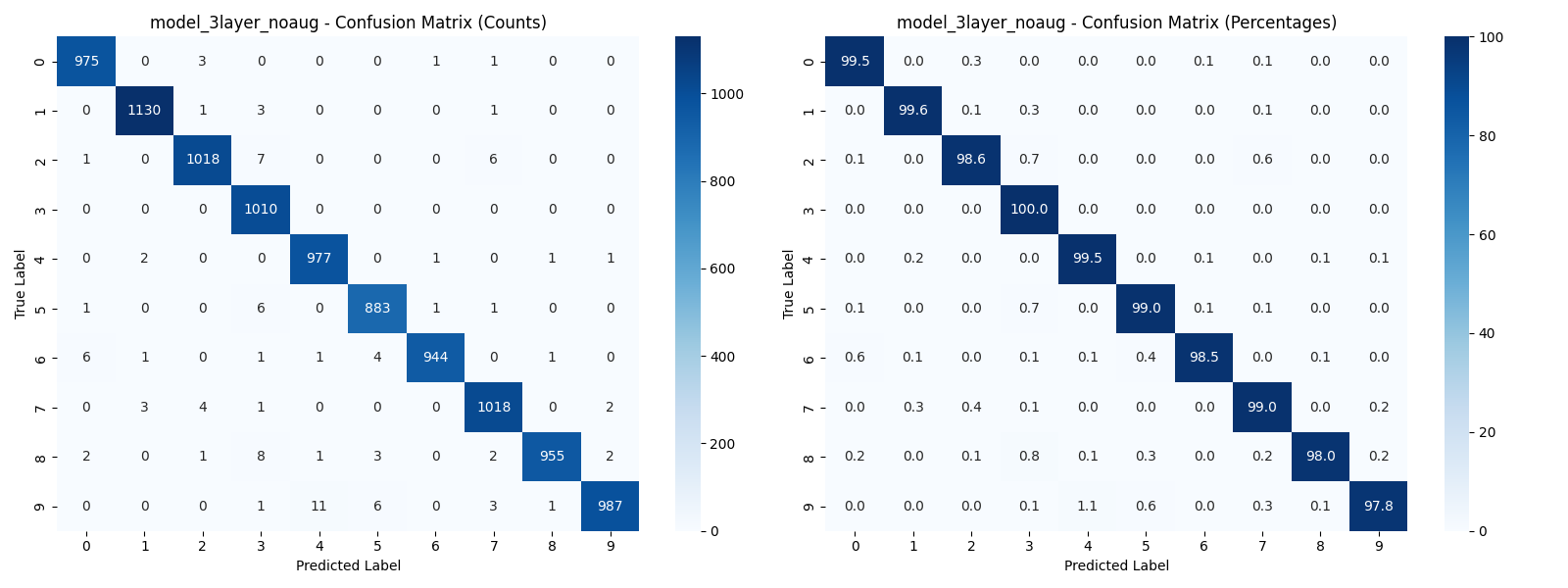
- Confusion matrices with both raw counts and percentages for detailed error analysis
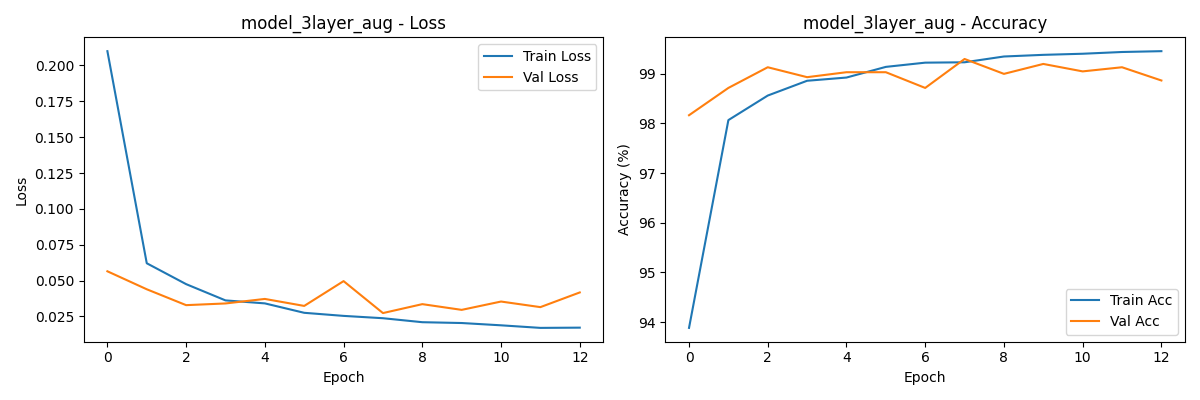
- Training history plots showing loss and accuracy curves across epochs
- Automatic model saving with timestamps and accuracy in the filename
- Early stopping to prevent overfitting
- Windows compatible with proper multiprocessing handling
Architecture
The project is built around three CNN models of increasing complexity:
| Model | Conv Layers | Filters | Batch Norm | Dropout | Typical Accuracy |
|---|---|---|---|---|---|
| 1-Layer | 1 | 32 | Yes | No | ~98-98.50% |
| 2-Layer | 2 | 32, 64 | Yes | 0.2 | ~99-99.15% |
| 3-Layer (no aug) | 3 | 32, 64, 128 | Yes | 0.3 | ~99.10%+ |
| 3-Layer (with aug) | 3 | 32, 64, 128 | Yes | 0.3 | ~99.20%+ |
Key technical decisions:
- PyTorch over TensorFlow — chosen for its Pythonic API and easier debugging, which is better for learning
- Validation split from training data (90/10) — keeps the official test set completely untouched for fair evaluation
- Augmentation only on training data — rotation, affine transforms, and random erasing to improve generalization without contaminating validation/test evaluation
num_workers=2withpersistent_workers— balanced for Windows compatibility while still allowing parallel data loading- Timestamped output directories — each training run saves to its own folder so results are never overwritten
The pipeline flow:
Load Data → Apply Transforms → Train Model → Validate → Save Best → Plot Results
Example Output
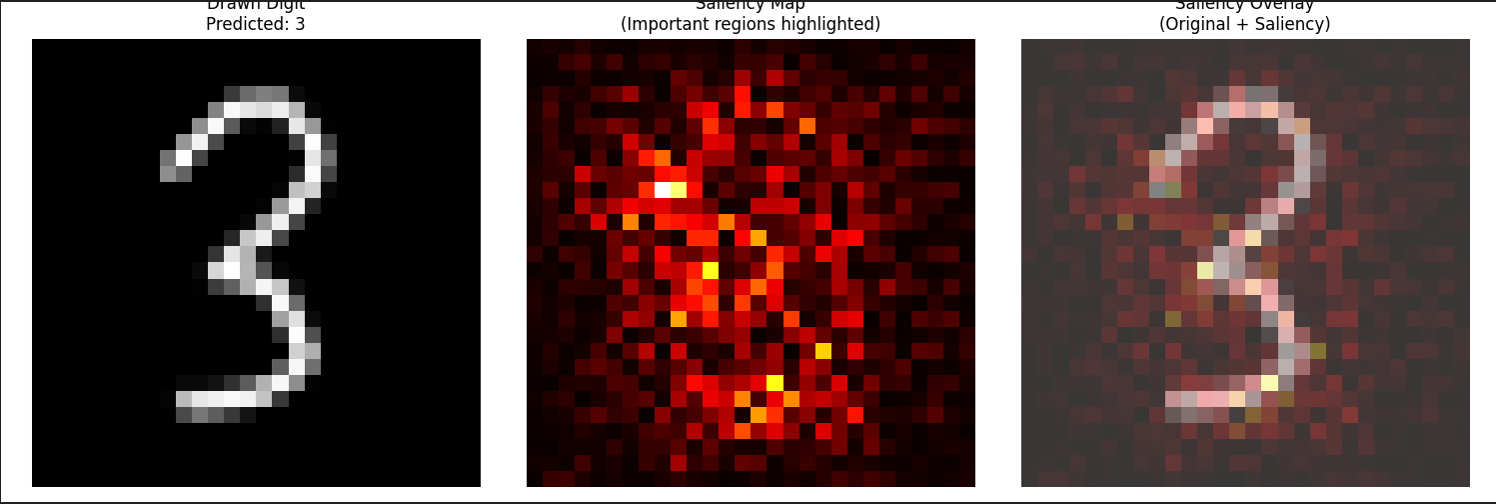
Hand-drawn digit 3 using the built-in drawing tool:

Prediction result with saliency map from the best trained model:
Learnings
- Adding more layers improves accuracy — Model 1 (1 layer) reached ~98.38%, Model 2 (2 layers) hit ~99.12%, and Model 3 (3 layers) achieved ~99.33%. More layers help, but the gains get smaller each time. For simple datasets like MNIST, you don't need a massive network.
- Data augmentation helps — training Model 3 with augmentation improved accuracy from ~99.13% to ~99.33%, showing that even small transforms like rotation and affine shifts make a real difference.
- Saliency maps build intuition — seeing which pixels the model focuses on helped me understand what the network actually learns vs. what I assumed it learns.
- Batch normalization and dropout work together — adding both to deeper models stabilized training and reduced overfitting noticeably.
- Separating training and validation data matters — keeping validation data completely separate from training prevents data contamination and ensures accuracy metrics reflect real generalization, not memorization.
- Versioning and naming outputs is essential — saving models with timestamps and accuracy in the filename makes it easy to find the best model later and compare results across different training runs.
- Understanding your training data matters — MNIST digits have white strokes on a black background. When testing with hand-drawn digits on a white background, predictions were poor until the input was inverted to match the training data format. This highlights the importance of having varied training data so the model learns actual features instead of memorizing patterns.